Tutorial
Data skew in Flink SQL
Data processing in real-time has become crucial for businesses, and Apache Flink, with its powerful stream processing capabilities, is at the…
Read moreIn the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as transformative tools. They’ve gone from powering simple demos to becoming integral components of sophisticated enterprise applications. Nevertheless, as organizations seek to deploy these systems at scale, a new discipline has arisen: LLMOps. In a recent webinar, Marek Wiewiórka, Chief Data Architect at Getting Data | Part of Xebia, provided invaluable insights into this field, discussing how to transition from playground experiments to production-ready generative AI systems.
Watch the webinar on demand, and let’s dive into the highlights from the session.
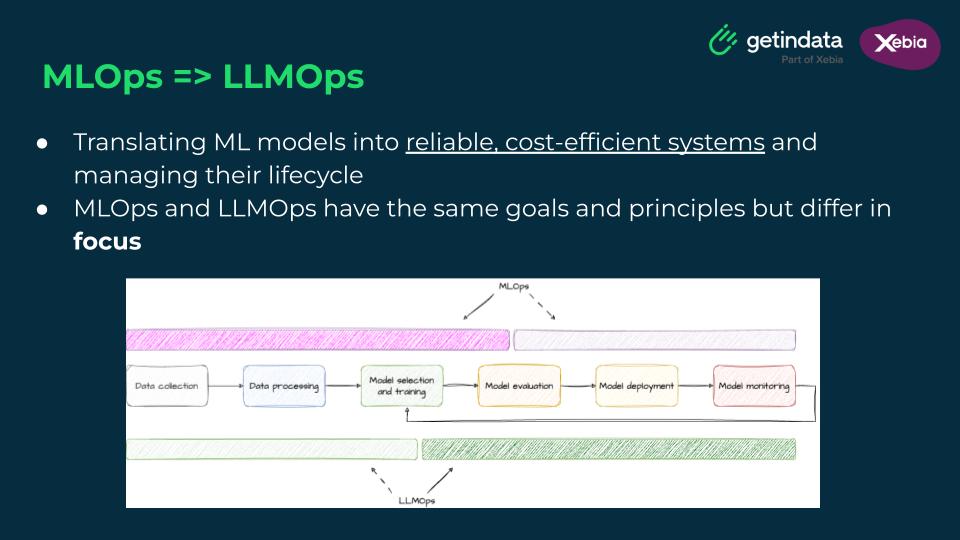
Many AI practitioners are familiar with MLOps, the operational backbone for deploying and managing machine learning models. But LLMOps, while sharing some similarities, diverges in key ways:
Marek outlined several challenges unique to deploying LLMs in enterprise contexts:
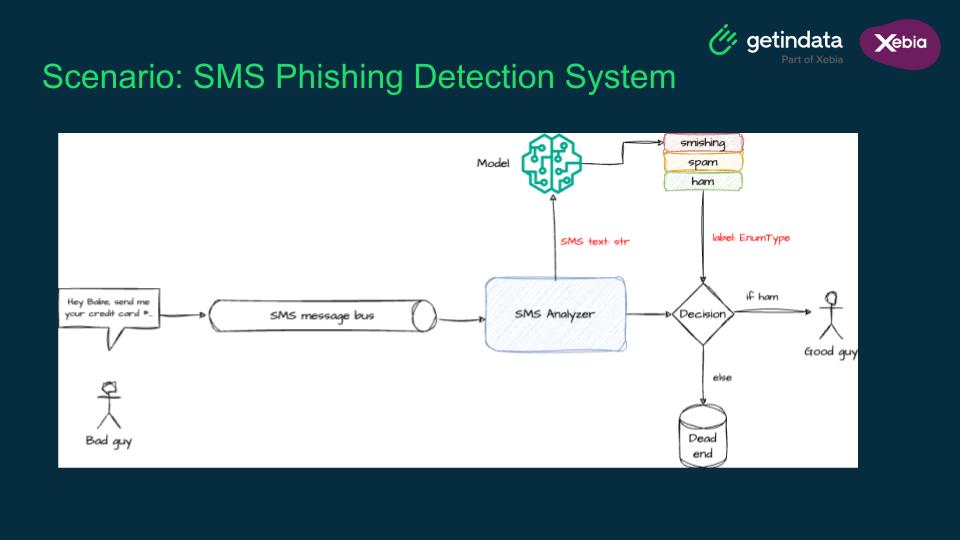
Marek shared an inspiring example of transitioning from a simple demo to a production-ready system. The project involved building an SMS phishing detection system powered by LLMs. Here’s a summary of the process:
The webinar showcased practical tools and frameworks for implementing LLMOps, including:
These tools enable developers to automate traditionally manual tasks, making large-scale deployments more feasible and efficient.
LLMOps is not just a scaled-up version of MLOps - it’s a new paradigm tailored for the unique demands of generative AI. As enterprises embrace these models, they must also grapple with governance, security and cost-efficiency. Marek emphasized that building production-grade systems demands automation, robust evaluation processes and a willingness to adapt to the fast-paced evolution of AI.
As LLMs continue to transform industries, LLMOps is becoming an indispensable discipline for AI practitioners. Whether you're building the next-gen co-pilot or a secure SMS filter, the principles outlined in this webinar can guide your journey from experimentation to enterprise-scale deployment.
For more details, check out the GitHub Repository: https://github.com/mwiewior/llmops-webinar with a demo code, or watch the full webinar recording.
Let’s turn ideas into action! 🚀
Data processing in real-time has become crucial for businesses, and Apache Flink, with its powerful stream processing capabilities, is at the…
Read moreRecently we published the first ebook in the area of MLOps: "Power Up Machine Learning Process. Build Feature Stores Faster - an Introduction to…
Read moreNowadays, companies need to deal with the processing of data collected in the organization data lake. As a result, data pipelines are becoming more…
Read moreCoronavirus is spreading through the world. At the moment of writing this post (on the 26th of March 2020) over 475k people have been infected and…
Read moreIntroduction - what are Flame Graphs? In Developer life there is a moment when the application that we create does not work as efficiently as we would…
Read moreData Pipeline Evolution The LinkedIn Engineering blog is a great resource of technical blog posts related to building and using large-scale data…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?